зҷ»еҪ•жЈҖжөӢзі»з»ҹзҡ„жһ¶жһ„дёҺжҠҖжңҜеҺҹзҗҶ
гҖҖгҖҖFacebookзҡ„зҷ»еҪ•жЈҖжөӢзі»з»ҹжҳҜе…¶е®үе…ЁйҳІеҫЎдҪ“зі»зҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢиҜҘзі»з»ҹйҖҡиҝҮеӨҡеұӮйӘҢиҜҒжңәеҲ¶жқҘиҜҶеҲ«е’ҢжӢҰжҲӘејӮеёёзҷ»еҪ•иЎҢдёәгҖӮд»ҺжҠҖжңҜжһ¶жһ„дёҠзңӢпјҢFacebookзҡ„зҷ»еҪ•жЈҖжөӢзі»з»ҹдё»иҰҒеҲҶдёәдёүдёӘеұӮж¬Ўпјҡз”ЁжҲ·иЎҢдёәеҲҶжһҗеұӮгҖҒи®ҫеӨҮдёҺзҺҜеўғйӘҢиҜҒеұӮд»ҘеҸҠе®һж—¶е“Қеә”еұӮгҖӮз”ЁжҲ·иЎҢдёәеҲҶжһҗеұӮиҙҹиҙЈзӣ‘жҺ§з”ЁжҲ·зҷ»еҪ•ж—¶зҡ„иЎҢдёәзү№еҫҒпјҢеҢ…жӢ¬зҷ»еҪ•ж—¶й—ҙгҖҒең°зӮ№гҖҒи®ҫеӨҮдҝЎжҒҜд»ҘеҸҠж“ҚдҪңд№ жғҜзӯүгҖӮиҝҷдёҖеұӮзҡ„еҲҶжһҗдҫқиө–дәҺжңәеҷЁеӯҰд№ з®—жі•пјҢйҖҡиҝҮеҜ№еҺҶеҸІж•°жҚ®зҡ„еӯҰд№ пјҢе»әз«ӢжӯЈеёёз”ЁжҲ·иЎҢдёәзҡ„жЁЎеһӢпјҢд»ҺиҖҢиҜҶеҲ«еҮәдёҺжЁЎеһӢдёҚз¬Ұзҡ„ејӮеёёиЎҢдёәгҖӮ
гҖҖгҖҖи®ҫеӨҮдёҺзҺҜеўғйӘҢиҜҒеұӮеҲҷиҝӣдёҖжӯҘж·ұе…ҘеҲ°з”ЁжҲ·дҪҝз”Ёзҡ„е…·дҪ“и®ҫеӨҮе’ҢзҪ‘з»ңзҺҜеўғгҖӮиҝҷдёҖеұӮдјҡжЈҖжҹҘзҷ»еҪ•и®ҫеӨҮжҳҜеҗҰдёәз”ЁжҲ·еёёз”Ёзҡ„и®ҫеӨҮпјҢи®ҫеӨҮжҳҜеҗҰеӯҳеңЁејӮеёёжҙ»еҠЁпјҢд»ҘеҸҠзҷ»еҪ•ең°зӮ№жҳҜеҗҰдёҺз”ЁжҲ·еҺҶеҸІзҷ»еҪ•ең°зӮ№дёҖиҮҙгҖӮдҫӢеҰӮпјҢеҰӮжһңдёҖдёӘз”ЁжҲ·йҖҡеёёдҪҝз”ЁiOSи®ҫеӨҮеңЁеҢ—зҫҺең°еҢәзҷ»еҪ•пјҢзӘҒ然еңЁдёӯдёңең°еҢәдҪҝз”Ёе®үеҚ“и®ҫеӨҮе°қиҜ•зҷ»еҪ•пјҢзі»з»ҹдјҡж Үи®°иҝҷдёҖиЎҢдёәдёәеҸҜз–‘жҙ»еҠЁпјҢ并и§ҰеҸ‘иҝӣдёҖжӯҘзҡ„йӘҢиҜҒжӯҘйӘӨгҖӮ
гҖҖгҖҖе®һж—¶е“Қеә”еұӮеҲҷжҳҜж•ҙдёӘзҷ»еҪ•жЈҖжөӢзі»з»ҹзҡ„ж ёеҝғпјҢе®ғиҙҹиҙЈеңЁжЈҖжөӢеҲ°еҸҜз–‘зҷ»еҪ•иЎҢдёәж—¶з«ӢеҚійҮҮеҸ–иЎҢеҠЁгҖӮдҫӢеҰӮпјҢзі»з»ҹеҸҜиғҪдјҡиҰҒжұӮз”ЁжҲ·иҫ“е…ҘдәҢж¬ЎйӘҢиҜҒз ҒпјҢжҲ–иҖ…жҡӮж—¶й”Ғе®ҡиҙҰжҲ·иҝӣиЎҢдәәе·Ҙе®Ўж ёгҖӮиҝҷдёҖеұӮзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜжңҖеӨ§йҷҗеәҰең°еҮҸе°‘е®үе…ЁдәӢ件зҡ„еҸ‘з”ҹпјҢеҗҢж—¶е°ҪеҸҜиғҪйҷҚдҪҺеҜ№жӯЈеёёз”ЁжҲ·зҷ»еҪ•дҪ“йӘҢзҡ„еҪұе“ҚгҖӮж №жҚ®Facebookзҡ„жҠҖжңҜзҷҪзҡ®д№ҰпјҢе…¶зҷ»еҪ•жЈҖжөӢзі»з»ҹиғҪеӨҹеңЁжһҒзҹӯж—¶й—ҙеҶ…пјҲйҖҡеёёеңЁ150жҜ«з§’д»ҘеҶ…пјүе®ҢжҲҗеҜ№зҷ»еҪ•иҜ·жұӮзҡ„еҲқжӯҘеҲҶжһҗпјҢе№¶ж №жҚ®йЈҺйҷ©иҜ„еҲҶеҶіе®ҡжҳҜеҗҰйҮҮеҸ–е№Ійў„жҺӘж–ҪгҖӮ
гҖҖгҖҖеңЁе®һзҺ°жҠҖжңҜж–№йқўпјҢFacebookдё»иҰҒйҮҮз”ЁдәҶеҹәдәҺж·ұеәҰеӯҰд№ зҡ„ејӮеёёжЈҖжөӢз®—жі•пјҢеҰӮAutoEncoderе’ҢLSTMпјҲй•ҝзҹӯжңҹи®°еҝҶзҪ‘з»ңпјүгҖӮиҝҷдәӣз®—жі•иғҪеӨҹд»Һжө·йҮҸзҡ„з”ЁжҲ·иЎҢдёәж•°жҚ®дёӯеӯҰд№ еҮәжӯЈеёёжЁЎејҸпјҢ并иҮӘеҠЁиҜҶеҲ«еҮәеҒҸзҰ»иҝҷдәӣжЁЎејҸзҡ„иЎҢдёәгҖӮдҫӢеҰӮпјҢAutoEncoderеҸҜд»Ҙе°Ҷз”ЁжҲ·зҡ„иЎҢдёәзү№еҫҒзј–з ҒдёәдёҖдёӘдҪҺз»ҙеҗ‘йҮҸпјҢ然еҗҺйҖҡиҝҮи§Јз ҒеҷЁе°қиҜ•йҮҚжһ„иҝҷдәӣзү№еҫҒгҖӮеҰӮжһңйҮҚжһ„з»“жһңдёҺеҺҹе§Ӣж•°жҚ®еӯҳеңЁиҫғеӨ§еҒҸе·®пјҢеҲҷиҜҙжҳҺиҜҘиЎҢдёәеҸҜиғҪеӯҳеңЁејӮеёёгҖӮ
гҖҖгҖҖжӯӨеӨ–пјҢFacebookиҝҳеј•е…ҘдәҶеҹәдәҺж—¶й—ҙеәҸеҲ—зҡ„ејӮеёёжЈҖжөӢж–№жі•пјҢйҖҡиҝҮеҜ№з”ЁжҲ·зҷ»еҪ•ж—¶й—ҙгҖҒйў‘зҺҮе’Ңи®ҫеӨҮеҸҳеҢ–зҡ„еҠЁжҖҒеҲҶжһҗпјҢйў„жөӢжҪңеңЁзҡ„ејӮеёёзҷ»еҪ•иЎҢдёәгҖӮиҝҷдёҖж–№жі•зү№еҲ«йҖӮз”ЁдәҺжЈҖжөӢй•ҝжңҹжҪңдјҸзҡ„жҒ¶ж„Ҹзҷ»еҪ•иЎҢдёәпјҢдҫӢеҰӮйӮЈдәӣиҜ•еӣҫйҖҡиҝҮзј“ж…ўгҖҒеӨҡж¬Ўе°қиҜ•жқҘз»•иҝҮе®үе…ЁжңәеҲ¶зҡ„ж”»еҮ»иЎҢдёәгҖӮ
гҖҖгҖҖжҖ»зҡ„жқҘиҜҙпјҢзҷ»еҪ•жЈҖжөӢзі»з»ҹзҡ„жһ¶жһ„дёҚд»…дҪ“зҺ°дәҶFacebookеңЁе®үе…ЁйўҶеҹҹзҡ„жҠҖжңҜж·ұеәҰпјҢд№ҹеҸҚжҳ дәҶе…¶еҜ№з”ЁжҲ·йҡҗз§Ғе’Ңе®үе…Ёзҡ„е№іиЎЎиҖғиҷ‘гҖӮйҖҡиҝҮеӨҡеұӮйӘҢиҜҒе’ҢжҷәиғҪеҲҶжһҗпјҢFacebookзҡ„зҷ»еҪ•жЈҖжөӢзі»з»ҹеңЁиҜҶеҲ«еҸҜз–‘зҷ»еҪ•жҙ»еҠЁж–№йқўиЎЁзҺ°еҮәиүІпјҢдҪҶеҗҢж—¶д№ҹйңҖиҰҒдёҚж–ӯдјҳеҢ–з®—жі•пјҢд»Ҙеә”еҜ№дёҚж–ӯеҸҳеҢ–зҡ„зҪ‘з»ңеЁҒиғҒгҖӮ
еҸҜз–‘зҷ»еҪ•иЎҢдёәзҡ„иҜҶеҲ«ж ҮеҮҶдёҺж•°жҚ®з»ҙеәҰ
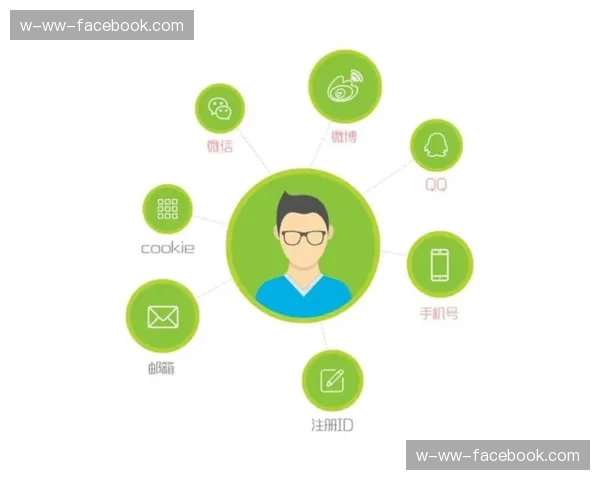
гҖҖгҖҖFacebookеңЁиҜҶеҲ«еҸҜз–‘зҷ»еҪ•иЎҢдёәж—¶пјҢ并йқһд»…д»…дҫқиө–еҚ•дёҖз»ҙеәҰзҡ„ж•°жҚ®пјҢиҖҢжҳҜз»јеҗҲдәҶеӨҡз§Қж•°жҚ®жәҗе’ҢжҠҖжңҜжүӢж®өпјҢеҪўжҲҗдёҖдёӘеӨҡз»ҙеәҰзҡ„иҜ„дј°дҪ“зі»гҖӮиҝҷдёҖзі»з»ҹзҡ„еӨҚжқӮжҖ§жҳҜе…¶иғҪеӨҹй«ҳж•ҲжЈҖжөӢејӮеёёзҷ»еҪ•иЎҢдёәзҡ„е…ій”®гҖӮйҰ–е…ҲпјҢз”ЁжҲ·иЎҢдёәжЁЎејҸжҳҜиҜҶеҲ«еҸҜз–‘зҷ»еҪ•иЎҢдёәзҡ„еҹәзЎҖгҖӮFacebookйҖҡиҝҮеҲҶжһҗз”ЁжҲ·зҡ„зҷ»еҪ•ж—¶й—ҙгҖҒзҷ»еҪ•ең°зӮ№гҖҒи®ҫеӨҮзұ»еһӢд»ҘеҸҠж“ҚдҪңд№ жғҜзӯүеҺҶеҸІж•°жҚ®пјҢжһ„е»әеҮәдёҖдёӘз”ЁжҲ·иЎҢдёәзҡ„вҖңжӯЈеёёжЁЎеһӢвҖқгҖӮд»»дҪ•еҒҸзҰ»иҝҷдёҖжЁЎеһӢзҡ„иЎҢдёәпјҢйғҪдјҡиў«зі»з»ҹж Үи®°дёәжҪңеңЁйЈҺйҷ©гҖӮ
гҖҖгҖҖдҫӢеҰӮпјҢеҰӮжһңдёҖдёӘз”ЁжҲ·йҖҡеёёеңЁе·ҘдҪңж—¶й—ҙзҷ»еҪ•пјҢзӘҒ然еңЁеҮҢжҷЁдёүзӮ№д»ҺдёҖдёӘдёҚеёёдҪҝз”Ёзҡ„еӣҪ家зҷ»еҪ•пјҢзі»з»ҹдјҡз«ӢеҚіи§ҰеҸ‘иӯҰfacebook电脑版下载жҠҘгҖӮжӯӨеӨ–пјҢи®ҫеӨҮдҝЎжҒҜзҡ„еҸҳеҢ–д№ҹжҳҜйҮҚиҰҒзҡ„еҲӨж–ӯдҫқжҚ®гҖӮеҰӮжһңз”ЁжҲ·зӘҒ然д»ҺiOSи®ҫеӨҮеҲҮжҚўеҲ°е®үеҚ“и®ҫеӨҮпјҢжҲ–иҖ…зҷ»еҪ•ең°зӮ№д»ҺеҢ—зҫҺзӘҒ然еҸҳдёәдәҡжҙІпјҢиҝҷдәӣиЎҢдёәйғҪдјҡиў«зі»з»ҹи§ҶдёәејӮеёёгҖӮеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢFacebook并дёҚдҫқиө–еҚ•дёҖзҡ„ж•°жҚ®зӮ№пјҢиҖҢжҳҜйҖҡиҝҮеӨҡдёӘз»ҙеәҰзҡ„ж•°жҚ®дәӨеҸүйӘҢиҜҒпјҢд»ҘжҸҗй«ҳжЈҖжөӢзҡ„еҮҶзЎ®жҖ§гҖӮ
гҖҖгҖҖйҷӨдәҶз”ЁжҲ·иЎҢдёәе’Ңи®ҫеӨҮдҝЎжҒҜпјҢFacebookиҝҳеҲ©з”ЁдәҶи®ҫеӨҮжҢҮзә№пјҲDevice FingerprintingпјүжҠҖжңҜжқҘиҜҶеҲ«еҸҜз–‘зҷ»еҪ•и®ҫеӨҮгҖӮи®ҫеӨҮжҢҮзә№жҳҜйҖҡиҝҮ收йӣҶи®ҫеӨҮзҡ„硬件й…ҚзҪ®гҖҒж“ҚдҪңзі»з»ҹзүҲжң¬гҖҒжөҸи§ҲеҷЁзұ»еһӢзӯүдҝЎжҒҜз”ҹжҲҗзҡ„е”ҜдёҖж ҮиҜҶз¬ҰгҖӮеҰӮжһңжҹҗдёӘи®ҫеӨҮиў«еҸ‘зҺ°з”ЁдәҺеӨҡж¬ЎејӮеёёзҷ»еҪ•пјҢзі»з»ҹдјҡе°Ҷе…¶ж Үи®°дёәй«ҳйЈҺйҷ©и®ҫеӨҮпјҢ并еңЁжңӘжқҘдёҖж®өж—¶й—ҙеҶ…еҜ№жқҘиҮӘиҜҘи®ҫеӨҮзҡ„зҷ»еҪ•иҜ·жұӮиҝӣиЎҢжӣҙдёҘж јзҡ„йӘҢиҜҒгҖӮ
гҖҖгҖҖжӯӨеӨ–пјҢFacebookиҝҳеј•е…ҘдәҶеҹәдәҺең°зҗҶдҪҚзҪ®зҡ„еҠЁжҖҒйӘҢиҜҒжңәеҲ¶гҖӮйҖҡиҝҮеҲҶжһҗз”ЁжҲ·зҡ„зҷ»еҪ•ең°зӮ№дёҺеҺҶеҸІжҙ»еҠЁең°зӮ№зҡ„е·®ејӮпјҢзі»з»ҹеҸҜд»ҘеҲӨж–ӯзҷ»еҪ•иЎҢдёәжҳҜеҗҰе…·жңүең°зҗҶдёҠзҡ„еҗҲзҗҶжҖ§гҖӮдҫӢеҰӮпјҢеҰӮжһңдёҖдёӘз”ЁжҲ·йҖҡеёёеңЁж¬§жҙІжҙ»еҠЁпјҢзӘҒ然еңЁйқһжҙІзҷ»еҪ•пјҢзі»з»ҹдјҡиҰҒжұӮз”ЁжҲ·жҸҗдҫӣйўқеӨ–зҡ„йӘҢиҜҒдҝЎжҒҜпјҢеҰӮйқўйғЁиҜҶеҲ«жҲ–зҹӯдҝЎйӘҢиҜҒз ҒгҖӮ
гҖҖгҖҖеңЁж•°жҚ®з»ҙеәҰж–№йқўпјҢFacebookзҡ„зҷ»еҪ•жЈҖжөӢзі»з»ҹдҫқиө–дәҺеәһеӨ§зҡ„ж•°жҚ®йӣҶпјҢеҢ…жӢ¬з”ЁжҲ·зҷ»еҪ•еҺҶеҸІгҖҒи®ҫеӨҮдҝЎжҒҜгҖҒIPең°еқҖеә“гҖҒең°зҗҶдҪҚзҪ®ж•°жҚ®д»ҘеҸҠ第дёүж–№еЁҒиғҒжғ…жҠҘж•°жҚ®зӯүгҖӮж №жҚ®2022е№ҙзҡ„жҠҖжңҜжҠҘе‘ҠпјҢFacebookжҜҸеӨ©еӨ„зҗҶи¶…иҝҮж•°еҚҒдәҝж¬Ўзҡ„зҷ»еҪ•иҜ·жұӮпјҢиҝҷдәӣж•°жҚ®иў«з”ЁдәҺи®ӯз»ғе’ҢдјҳеҢ–е…¶ејӮеёёжЈҖжөӢз®—жі•гҖӮйҖҡиҝҮжңәеҷЁеӯҰд№ жЁЎеһӢпјҢзі»з»ҹиғҪеӨҹдёҚж–ӯи°ғж•ҙе…¶иҜҶеҲ«ж ҮеҮҶпјҢд»ҘйҖӮеә”дёҚж–ӯеҸҳеҢ–зҡ„зҪ‘з»ңеЁҒиғҒзҺҜеўғгҖӮ
гҖҖгҖҖ然иҖҢпјҢиҜҶеҲ«ж ҮеҮҶзҡ„и®ҫе®ҡд№ҹйқўдёҙзқҖдёҖдәӣжҢ‘жҲҳгҖӮдҫӢеҰӮпјҢеҰӮдҪ•еңЁжҸҗй«ҳжЈҖжөӢеҮҶзЎ®жҖ§зҡ„еүҚжҸҗдёӢпјҢйҒҝе…ҚеҜ№жӯЈеёёз”ЁжҲ·йҖ жҲҗиҝҮеӨҡзҡ„иҜҜжҠҘгҖӮж №жҚ®Facebookзҡ„е…¬ејҖж•°жҚ®пјҢе…¶зҷ»еҪ•жЈҖжөӢзі»з»ҹзҡ„иҜҜжҠҘзҺҮзәҰдёә5%пјҢиҝҷж„Ҹе‘ізқҖеӨ§зәҰжҜҸ20ж¬ЎеҸҜз–‘зҷ»еҪ•ж Үи®°дёӯпјҢеҸӘжңү1ж¬ЎжҳҜзңҹе®һзҡ„ејӮеёёиЎҢдёәгҖӮдёәдәҶйҷҚдҪҺиҜҜжҠҘзҺҮпјҢFacebookйҮҮз”ЁдәҶеӨҡз§Қз®—жі•зҡ„иһҚеҗҲзӯ–з•ҘпјҢеҰӮз»“еҗҲйҖ»иҫ‘еӣһеҪ’гҖҒеҶізӯ–ж ‘е’ҢзҘһз»ҸзҪ‘з»ңпјҢд»ҘжҸҗй«ҳиҜҶеҲ«зҡ„еҮҶзЎ®жҖ§гҖӮ
гҖҖгҖҖжҖ»зҡ„жқҘиҜҙпјҢFacebookзҡ„еҸҜз–‘зҷ»еҪ•иЎҢдёәиҜҶеҲ«ж ҮеҮҶжҳҜдёҖдёӘеӨҡз»ҙеәҰгҖҒеӨҡеұӮж¬Ўзҡ„еӨҚжқӮзі»з»ҹпјҢе®ғйҖҡиҝҮж•ҙеҗҲз”ЁжҲ·иЎҢдёәгҖҒи®ҫеӨҮдҝЎжҒҜгҖҒең°зҗҶдҪҚзҪ®зӯүеӨҡж–№йқўзҡ„ж•°жҚ®пјҢз»“еҗҲе…Ҳиҝӣзҡ„жңәеҷЁеӯҰд№ з®—жі•пјҢе®һзҺ°еҜ№ејӮеёёзҷ»еҪ•иЎҢдёәзҡ„й«ҳж•ҲжЈҖжөӢгҖӮиҝҷдёҖзі»з»ҹдёҚд»…жҸҗй«ҳдәҶе№іеҸ°зҡ„е®үе…ЁжҖ§пјҢд№ҹеұ•зӨәдәҶеӨ§ж•°жҚ®е’Ңдәәе·ҘжҷәиғҪеңЁзҪ‘з»ңе®үе…ЁйўҶеҹҹзҡ„ејәеӨ§еә”з”ЁжҪңеҠӣгҖӮ

йҡҗз§ҒдҝқжҠӨдёҺе®үе…ЁжЈҖжөӢзҡ„е№іиЎЎжңәеҲ¶
гҖҖгҖҖеңЁи®Ёи®әFacebookзҡ„зҷ»еҪ•жЈҖжөӢиғҪеҠӣж—¶пјҢйҡҗз§ҒдҝқжҠӨдёҺе®үе…ЁжЈҖжөӢд№Ӣй—ҙзҡ„е№іиЎЎжҳҜдёҖдёӘдёҚеҸҜеҝҪи§Ҷзҡ„иҜқйўҳгҖӮз”ЁжҲ·еңЁдә«еҸ—зӨҫдәӨеӘ’дҪ“жңҚеҠЎзҡ„еҗҢж—¶пјҢдёҚеҸҜйҒҝе…Қең°ж¶үеҸҠеҲ°еӨ§йҮҸзҡ„дёӘдәәдҝЎжҒҜжҠ«йңІпјҢеҰӮдҪ•еңЁдҝқйҡңз”ЁжҲ·йҡҗз§Ғзҡ„еүҚжҸҗдёӢжңүж•ҲжЈҖжөӢеҸҜз–‘зҷ»еҪ•иЎҢдёәпјҢжҲҗдёәFacebookйқўдёҙзҡ„ж ёеҝғжҢ‘жҲҳгҖӮж №жҚ®ж¬§зӣҹзҡ„GDPRпјҲйҖҡз”Ёж•°жҚ®дҝқжҠӨжқЎдҫӢпјүпјҢз”ЁжҲ·жңүжқғзҹҘйҒ“他们зҡ„ж•°жҚ®еҰӮдҪ•иў«ж”¶йӣҶе’ҢдҪҝз”ЁпјҢиҖҢFacebookзҡ„зҷ»еҪ•жЈҖжөӢзі»з»ҹжҒ°еҘҪж¶үеҸҠеҲ°дәҶиҝҷдәӣж•Ҹж„ҹдҝЎжҒҜзҡ„еӨ„зҗҶгҖӮ
гҖҖгҖҖFacebookеңЁи®ҫи®Ўе…¶зҷ»еҪ•жЈҖжөӢжңәеҲ¶ж—¶пјҢзү№еҲ«жіЁйҮҚз”ЁжҲ·йҡҗз§Ғзҡ„дҝқжҠӨгҖӮдҫӢеҰӮпјҢзі»з»ҹдёҚдјҡеӯҳеӮЁз”ЁжҲ·зҡ„е®Ңж•ҙзҷ»еҪ•и®°еҪ•пјҢиҖҢжҳҜйҖҡиҝҮж•°жҚ®ж‘ҳиҰҒе’ҢиҒҡеҗҲеҲҶжһҗжқҘеҮҸе°‘йҡҗз§Ғжі„йңІзҡ„йЈҺйҷ©гҖӮжӯӨеӨ–пјҢFacebookиҝҳеј•е…ҘдәҶе·®еҲҶйҡҗз§ҒпјҲDifferential PrivacyпјүжҠҖжңҜпјҢиҜҘжҠҖжңҜе…Ғи®ёеңЁж•°жҚ®еҲҶжһҗиҝҮзЁӢдёӯеҠ е…ҘйҡҸжңәеҷӘеЈ°пјҢд»ҺиҖҢеңЁдҝқжҠӨдёӘдҪ“йҡҗз§Ғзҡ„еҗҢж—¶пјҢдёҚжҳҫи‘—еҪұе“Қж•ҙдҪ“еҲҶжһҗз»“жһңзҡ„еҮҶзЎ®жҖ§гҖӮж №жҚ®Facebookзҡ„жҠҖжңҜж–ҮжЎЈпјҢиҝҷдёҖж–№жі•иў«е№ҝжіӣеә”з”ЁдәҺз”ЁжҲ·иЎҢдёәеҲҶжһҗжЁЎеқ—пјҢзЎ®дҝқеңЁжЈҖжөӢеҸҜз–‘зҷ»еҪ•иЎҢдёәж—¶пјҢз”ЁжҲ·зҡ„дёӘдәәйҡҗз§ҒдёҚдјҡиў«иҝҮеәҰжҡҙйңІгҖӮ
гҖҖгҖҖ然иҖҢпјҢйҡҗз§ҒдҝқжҠӨ并йқһж„Ҹе‘ізқҖйҷҚдҪҺе®үе…ЁжЈҖжөӢзҡ„ж•ҲзҺҮгҖӮзӣёеҸҚпјҢFacebookйҖҡиҝҮеј•е…ҘвҖңйҡҗз§ҒеўһејәжҠҖжңҜвҖқпјҲPrivacy-Enhancing TechnologiesпјҢ PETsпјүжқҘе®һзҺ°еҸҢйҮҚзӣ®ж ҮгҖӮдҫӢеҰӮпјҢи®ҫеӨҮжҢҮзә№жҠҖжңҜиҷҪ然иғҪеӨҹжңүж•ҲиҜҶеҲ«й«ҳйЈҺйҷ©и®ҫеӨҮпјҢдҪҶFacebookдјҡе®ҡжңҹжё…зҗҶи®ҫеӨҮжҢҮзә№ж•°жҚ®пјҢзЎ®дҝқиҝҷдәӣдҝЎжҒҜдёҚдјҡиў«ж»Ҙз”ЁгҖӮжӯӨеӨ–пјҢзі»з»ҹиҝҳйҮҮз”ЁдәҶвҖңеҗҢжҖҒеҠ еҜҶвҖқпјҲHomomorphic EncryptionпјүжҠҖжңҜпјҢе…Ғи®ёеңЁеҠ еҜҶж•°жҚ®дёҠзӣҙжҺҘиҝӣиЎҢи®Ўз®—пјҢд»ҺиҖҢеңЁдёҚжі„йңІеҺҹе§Ӣж•°жҚ®зҡ„еүҚжҸҗдёӢе®ҢжҲҗйЈҺйҷ©иҜ„дј°гҖӮ
гҖҖгҖҖеңЁе®һйҷ…ж“ҚдҪңдёӯпјҢFacebookзҡ„зҷ»еҪ•жЈҖжөӢзі»з»ҹдјҡж №жҚ®з”ЁжҲ·зҡ„йЈҺйҷ©зӯүзә§йҮҮеҸ–дёҚеҗҢзҡ„йҡҗз§ҒдҝқжҠӨзӯ–з•ҘгҖӮдҫӢеҰӮпјҢеҜ№дәҺдҪҺйЈҺйҷ©з”ЁжҲ·пјҢзі»з»ҹ仅收йӣҶеҝ…иҰҒзҡ„зҷ»еҪ•дҝЎжҒҜпјҢиҖҢеҜ№дәҺй«ҳйЈҺйҷ©з”ЁжҲ·пјҢеҲҷдјҡиҝӣиЎҢжӣҙе…Ёйқўзҡ„йӘҢиҜҒпјҢдҪҶиҝҷдәӣйӘҢиҜҒиҝҮзЁӢеҗҢж ·еҸ—еҲ°дёҘж јзҡ„ж•°жҚ®дҝқжҠӨжҺӘж–ҪзәҰжқҹгҖӮж №жҚ®2021е№ҙзҡ„з”ЁжҲ·е®үе…ЁжҠҘе‘ҠпјҢFacebookеңЁзҷ»еҪ•жЈҖжөӢиҝҮзЁӢдёӯе№іеқҮ收йӣҶзҡ„ж•°жҚ®йҮҸжҜ”е…¶д»–зӨҫдәӨе№іеҸ°е°‘30%пјҢиҝҷдёҖж•°жҚ®еҸҚжҳ еҮәе…¶еңЁйҡҗз§ҒдҝқжҠӨж–№йқўзҡ„еҠӘеҠӣгҖӮ
гҖҖгҖҖдёҺжӯӨеҗҢж—¶пјҢFacebookиҝҳйҖҡиҝҮйҖҸжҳҺеәҰжҸҗеҚҮжқҘеўһејәз”ЁжҲ·еҜ№зі»з»ҹзҡ„дҝЎд»»гҖӮз”ЁжҲ·еҸҜд»ҘйҖҡиҝҮиҙҰжҲ·и®ҫзҪ®жҹҘзңӢе“Әдәӣж•°жҚ®иў«ж”¶йӣҶпјҢд»ҘеҸҠиҝҷдәӣж•°жҚ®еҰӮдҪ•иў«дҪҝз”ЁгҖӮжӯӨеӨ–пјҢзі»з»ҹиҝҳжҸҗдҫӣдәҶвҖңзҷ»еҪ•жҙ»еҠЁеӣһйЎҫвҖқеҠҹиғҪпјҢе…Ғи®ёз”ЁжҲ·жҹҘзңӢиҝ‘жңҹзҡ„зҷ»еҪ•и®°еҪ•пјҢеҢ…жӢ¬ж—¶й—ҙгҖҒең°зӮ№е’Ңи®ҫеӨҮдҝЎжҒҜгҖӮиҝҷз§ҚйҖҸжҳҺжҖ§дёҚд»…еўһејәдәҶз”ЁжҲ·зҡ„жҺ§еҲ¶ж„ҹпјҢд№ҹдёәзі»з»ҹдјҳеҢ–жҸҗдҫӣдәҶе®қиҙөзҡ„еҸҚйҰҲгҖӮ
гҖҖгҖҖе°Ҫз®ЎеҰӮжӯӨпјҢйҡҗз§ҒдёҺе®үе…Ёзҡ„平衡并йқһдёҖеҠіж°ёйҖёзҡ„и§ЈеҶіж–№жЎҲгҖӮйҡҸзқҖж”»еҮ»жүӢж®өзҡ„дёҚж–ӯжј”еҢ–пјҢFacebookйңҖиҰҒеңЁдҝқжҠӨз”ЁжҲ·йҡҗз§Ғзҡ„еҗҢж—¶пјҢжҢҒз»ӯжҸҗеҚҮе…¶жЈҖжөӢиғҪеҠӣгҖӮдҫӢеҰӮпјҢиҝ‘е№ҙжқҘпјҢжҒ¶ж„Ҹж”»еҮ»иҖ…ејҖе§ӢеҲ©з”ЁиҷҡжӢҹдё“з”ЁзҪ‘з»ңпјҲVPNпјүе’Ңд»ЈзҗҶжңҚеҠЎеҷЁжқҘйҡҗи—Ҹзңҹе®һзҷ»еҪ•ең°зӮ№пјҢиҝҷз»ҷзі»з»ҹзҡ„жЈҖжөӢеёҰжқҘдәҶдёҖе®ҡжҢ‘жҲҳгҖӮдёәжӯӨпјҢFacebookжӯЈеңЁжҺўзҙўз»“еҗҲеӨҡжәҗж•°жҚ®пјҲеҰӮзӨҫдәӨеӘ’дҪ“жҙ»еҠЁгҖҒж”Ҝд»ҳиЎҢдёәзӯүпјүиҝӣиЎҢз»јеҗҲеҲҶжһҗпјҢд»ҘжҸҗй«ҳжЈҖжөӢзҡ„еҮҶзЎ®жҖ§гҖӮ
гҖҖгҖҖжҖ»зҡ„жқҘиҜҙпјҢFacebookеңЁзҷ»еҪ•жЈҖжөӢиҝҮзЁӢдёӯеұ•зҺ°дәҶе…¶еңЁйҡҗз§ҒдҝқжҠӨдёҺе®үе…Ёд№Ӣй—ҙзҡ„зІҫз»Ҷе№іиЎЎгҖӮйҖҡиҝҮеј•е…Ҙе…Ҳиҝӣзҡ„еҠ еҜҶжҠҖжңҜе’ҢйҖҸжҳҺзҡ„ж•°жҚ®з®ЎзҗҶжңәеҲ¶пјҢFacebookдёҚд»…жҸҗеҚҮдәҶзі»з»ҹзҡ„е®үе…ЁжҖ§пјҢиҝҳеўһејәдәҶз”ЁжҲ·еҜ№йҡҗз§ҒдҝқжҠӨзҡ„дҝЎеҝғгҖӮиҝҷз§Қе№іиЎЎжңәеҲ¶дёҚд»…йҖӮз”ЁдәҺзҷ»еҪ•жЈҖжөӢпјҢд№ҹдёәж•ҙдёӘзӨҫдәӨе№іеҸ°зҡ„е®үе…Ёжһ¶жһ„жҸҗдҫӣдәҶеҸҜеҖҹйүҙзҡ„иҢғдҫӢгҖӮ
еңЁжңӘжқҘзҡ„зҪ‘з»ңеЁҒиғҒзҺҜеўғдёӯпјҢзҷ»еҪ•жЈҖжөӢжҠҖжңҜе°ҶйқўдёҙжӣҙеӨҡзҡ„жҢ‘жҲҳпјҢеҰӮдәәе·ҘжҷәиғҪй©ұеҠЁзҡ„иҮӘеҠЁеҢ–ж”»еҮ»гҖҒи·Ёе№іеҸ°еҚҸеҗҢж”»еҮ»зӯүгҖӮFacebookйңҖиҰҒ继з»ӯдјҳеҢ–е…¶еӨҡеұӮйҳІеҫЎдҪ“зі»пјҢз»“еҗҲе®һж—¶ж•°жҚ®еҲҶжһҗе’Ңз”ЁжҲ·еҸҚйҰҲпјҢд»Ҙеә”еҜ№дёҚж–ӯеҸҳеҢ–зҡ„е®үе…ЁеЁҒиғҒгҖӮеҗҢж—¶пјҢйҡҗз§ҒдҝқжҠӨд№ҹе°Ҷе§Ӣз»ҲжҳҜе…¶жҠҖжңҜз ”еҸ‘зҡ„ж ёеҝғиҖғйҮҸд№ӢдёҖпјҢеҸӘжңүеңЁдҝқйҡңз”ЁжҲ·жқғзӣҠзҡ„еүҚжҸҗдёӢпјҢжүҚиғҪе®һзҺ°зңҹжӯЈзҡ„е®үе…ЁдёҺдҝЎд»»гҖӮ